AI看图:基于卷积神经网络的股价走势识别与分类
【摘要】
本研究采用卷积神经网络(Convolutional Neural Network,CNN)对标准化价量数据图表和未来股价走势进行建模,以实现对未来股价走势的预测。实证结果表明,价量数据图表卷积神经网络取得了显著的选股收益。整体思路如下:
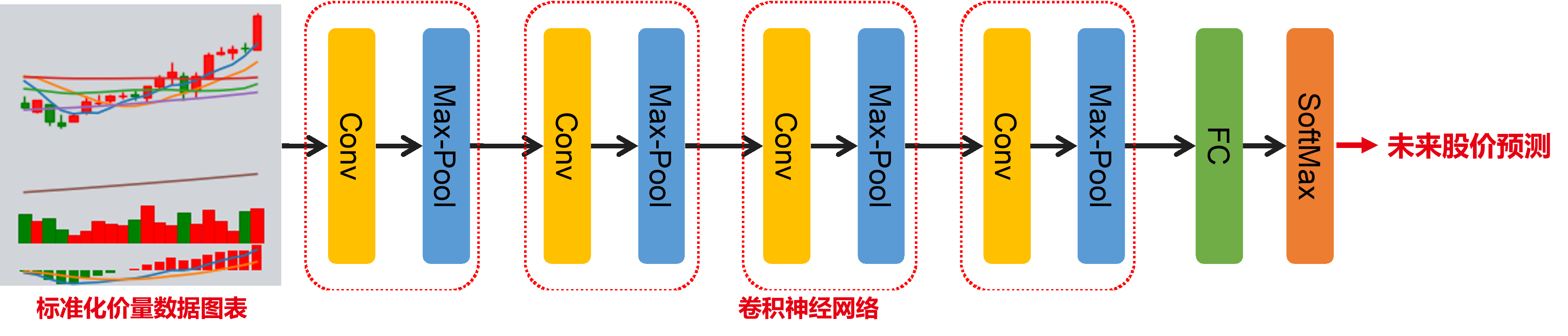
一、基于卷积神经网络的股价走势识别与分类
基于价量数据对未来股价走势进行预测作为一类重要的机器学习量化选股策略,在过去受到了广泛的研究和应用。由于个股的价量数据是随着交易活动的进行而产生的,其本质上是关于时间的一组序列。因此,为了建模价量数据与未来股价走势之间的关系,大多数研究方法自然而然地使用了循环神经网络(Recurrent Neural Network,RNN)或Transformer这两大类时序模型。
在这些方法中,模型的输入是关于价量数据的一维或多维数组,输出则是股价的未来走势。然而,尽管时序模型在一定程度上能够捕捉到价量序列中诸如价格、交易量的上涨或下跌及其相互交织的高维信息,但其无法对价格和交易量的走势形态及其变化进行有效识别。
举个例子对此进行解释。以人类视角来看,通常在对股价的未来走势进行预测时,并不会选择直接观测一组关于价量的序列,因为能从中捕获到的不只是数字上的涨跌。为了能更好地捕捉到价格和交易量的形态走势,通常会选择观测包含k线图、移动平均价、交易量、MACD数据的图表,而不是一组纯粹的数字。
因此,本研究从上述观点出发,舍弃了使用时序模型对序列数据进行建模的传统方法。取而代之的是,本研究采用卷积神经网络(Convolutional Neural Network,CNN)对标准化价量数据图表和未来股价走势进行建模,以实现对未来股价走势的预测。对此,本方法首先构建了包含k线图、移动平均价、交易量、MACD数据的标准化价量数据图表。然后,设计了能捕捉图表中价量数据走势形态的卷积神经网络来对其与未来股价走势进行建模。
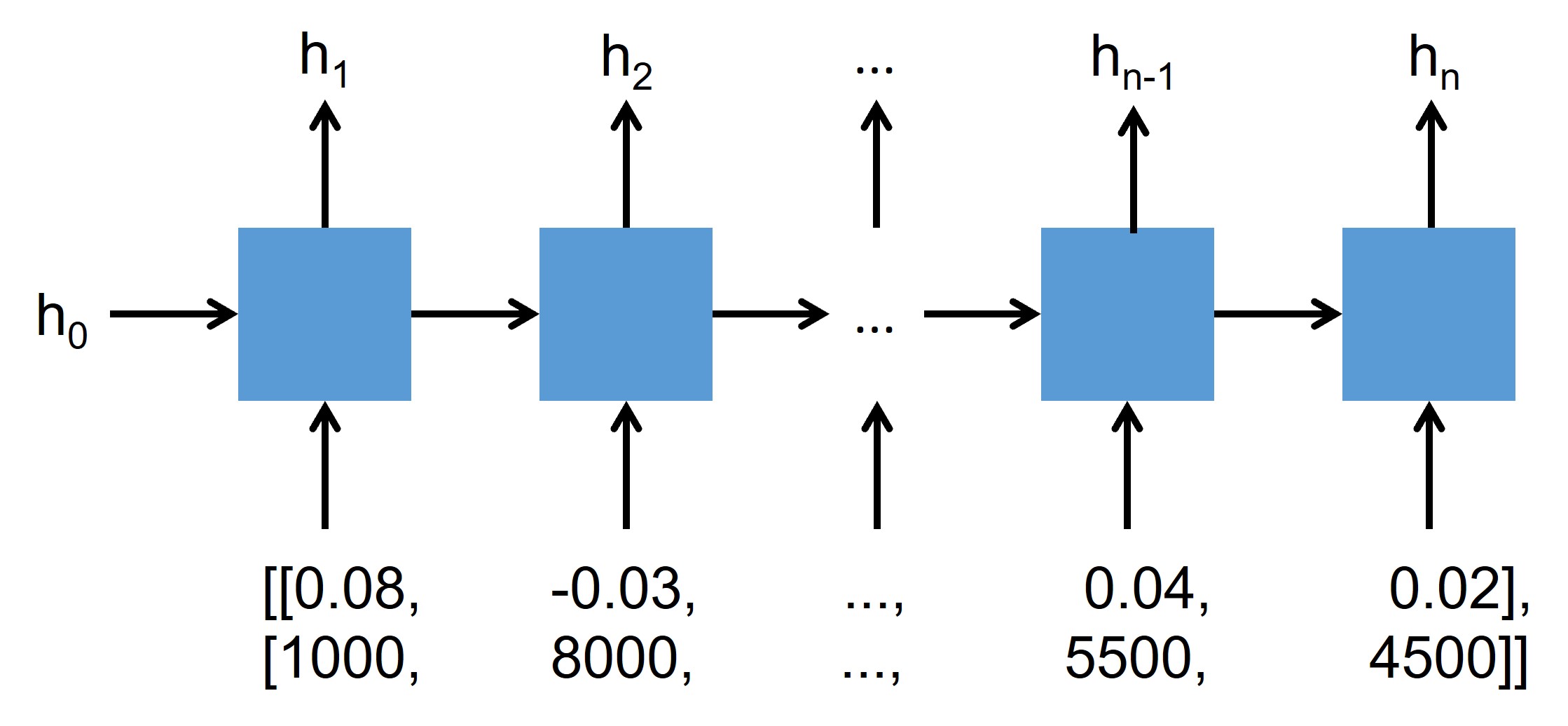
二、循环神经网络
循环神经网络(Recurrent Neural Network,RNN)是一类以序列数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接的递归神经网络。尽管循环神经网络演进出了长短期记忆(Long Short-Term Memory,LSTM)、门控循环单元(Gated Recurrent Units,GRU)等多种形式,但其基本结构相同,如图下所示。
假设该网络以一组包含价格和交易量的二维序列数据为输入,循环神经网络节点首先将初始化的隐藏层状态(Hidden State)h0和第一个时间节点上的价格和交易量数据(即0.08和1000)作为输入,在信息处理后输出下一个隐藏层状态h1。随后在下一个节点的计算中,则以上一个隐藏层状态h1和第二个时间节点上的价格和交易量数据(即-0.03和8000)作为输入,然后输出下一个隐藏层状态h2,如此进行直至处理完输入中的最后一个时间节点的数据。在处理完所有数据后,通常将最后一个隐藏层状态hn作为最终输出,使用一个前馈神经网络(Feedforward Neural Network)对其进行降维后与未来股价走势进行建模,以此来实现模型的训练和回测。
虽然此类循环神经网络在一定程度上能够捕捉到序列数据中的数字关系,但其无法对股票市场中价格和交易量的走势形态进行有效识别。
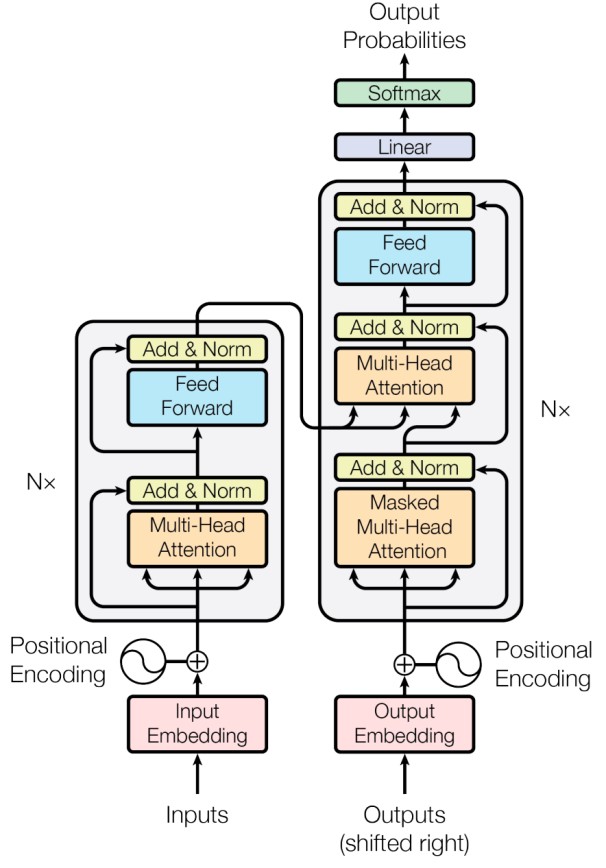
三、Transformer
Transformer是近年来受到广泛研究和应用的一种时序模型,其通过多头注意力机制(Multi-Head Attention)来捕获输入时序数据中的前后关系,结构如下图所示。与传统的循环神经网络相比,Transformer克服了短期记忆的缺点,具有能建模超长序列数据之间关系的能力。此外,Transformer能够并行化处理数据,替代了传统循环神经网络递归式处理数据的范式,大大提高了运算速度。
尽管如此,Transformer作为一个时序模型,其仍无法对股票市场中价格和交易量的走势形态进行有效识别。
四、卷积神经网络
卷积神经网络是当今计算机视觉领域的重要基础模型之一,其被广泛应用在图像识别领域。卷积神经网络的雏形为日本学者福岛邦彦(Kunihiko Fukushima)在其1979和1980年发表的论文中提出的Neocognitron模型。
Neocognitron模型由S层(Simple-Layer)和C层(Complex-Layer)构成,是一个具有深度结构的神经网络。其通过S层单元和C层单元分别对图像特征进行提取、接收和响应不同感受野返回的特征。由于Neocognitron模型初步实现了卷积神经网络中卷积层(Convolution Layer)和池化层(Pooling Layer)的功能,其在学界内被认为是卷积神经网络领域的开创性研究工作。
1987年,Alexander Waibel等提出第一个较为完备的卷积神经网络,即网络时间延迟网络(Time Delay Neural Network, TDNN)。TDNN使用FFT预处理的语音信号作为输入,由2个一维卷积核组成隐藏层,以提取语音信号频率域上的平移不变特征,其在语音识别领域上的表现超过了同等条件下当时的主流算法隐马尔可夫模型(Hidden Markov Model, HMM)。
1988年,第一个应用于医学影像检测的二维卷积神经网络由Wei Zhang等提出。1989年,Yann LeCun构建了包含2个卷积层、2个全连接层、共计6万个学习参数的卷积神经网络LeNet。在LeCun对其网络结构进行论述时首次使用了“卷积”一词,“卷积神经网络”因此得名。
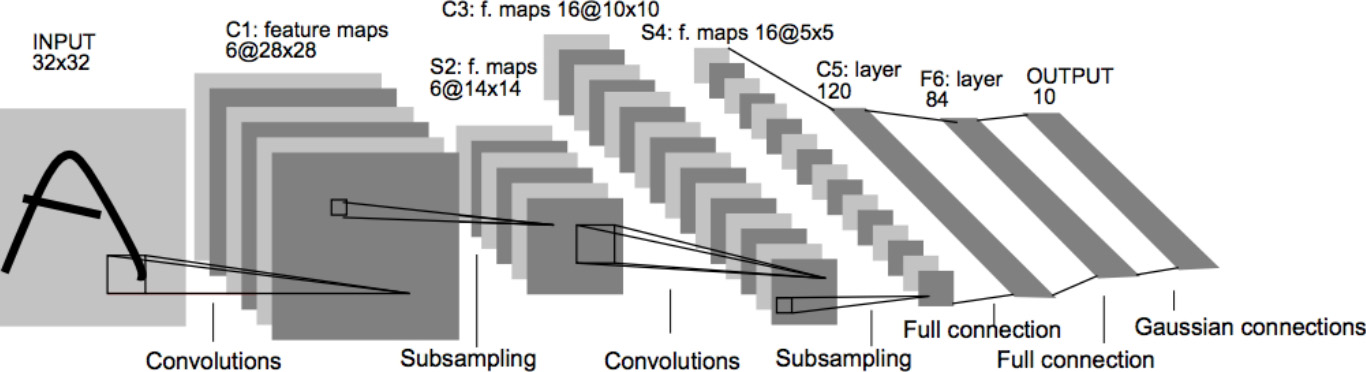
1998年,Yann LeCun等人在LeNet的基础上构建了更加完备的卷积神经网络LeNet-5。LeNet-5的结构如下图所示,其定义了现代卷积神经网络的基本结构。LeNet-5在手写数字识别任务上的成功使得卷积神经网络得到了广泛关注。2003年,微软基于卷积神经网络开发了光学字符读取(Optical Character Recognition,OCR)系统。
2006年,随着深度学习理论的提出,卷积神经网络的表征学习能力得到了更广泛的关注,并随着CPU、GPU等数值计算硬件设备的研发得到了快速发展。自2012年的AlexNet 开始,卷积神经网络多次成为ImageNet大规模视觉识别竞赛(ImageNet Large Scale Visual Recognition Challenge, ILSVRC)的优胜算法,包括2013年的ZFNet、2014年的VGGNet、GoogLeNet和2015年的ResNet。
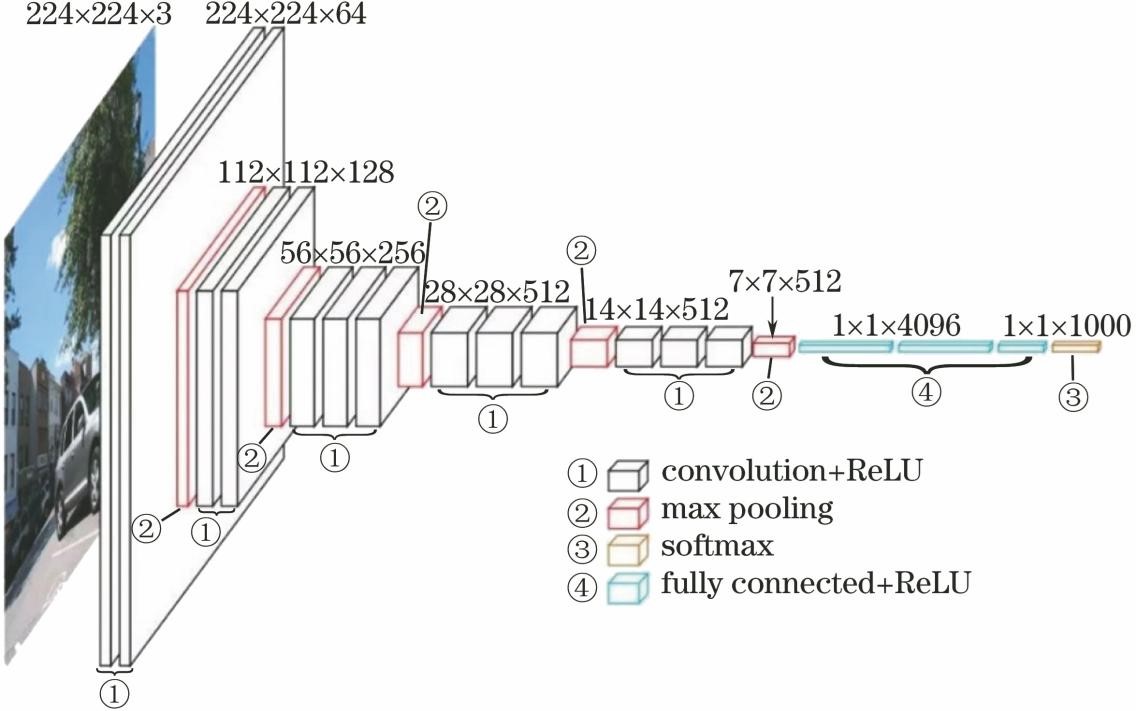
以图像识别中最经典的卷积神经网络VGG16为例,其共包含了13个卷积层、3个全连接层、3个最大值池化层以及一个softmax分类层,结构如下图所示。下面对卷积神经网络中的主要部分进行介绍。
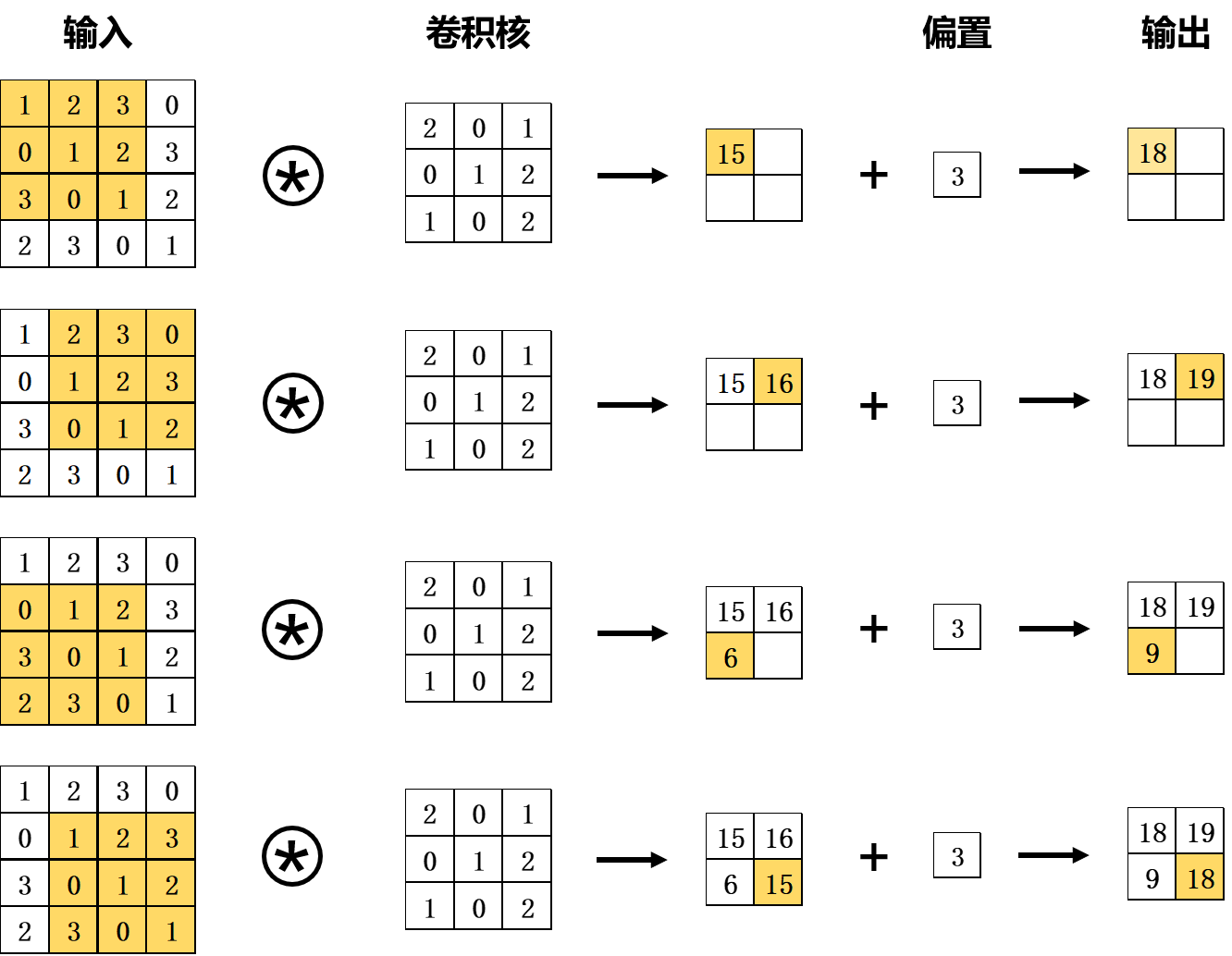
卷积神经网络的核心是卷积运算。卷积运算可以被理解为乘加运算,其目的与传统图像处理中的滤波器运算相似。如下图所示,将卷积核与输入数据进行卷积运算。在这个例子中,输入数据和卷积核都是有长和高的二维矩阵,输入的大小为(4,4),卷积核的大小为(3,3),输出的大小为(2,2)。如图中所示,在每个位置上将卷积核的元素与输入的元素相乘再求和,即乘积累加运算。然后将经过卷积核的运算结果输出到相应的位置。在逐次将卷积核与输入数据进行卷积运算并加上偏置量后即得到卷积层的输出。
由于模型运算的需要,通常在卷积运算前会通过填充(adding)操作向输入数据的周围填入固定的数值(比如0等)。如下图所示,将幅度为1的填充操作应用于输入大小为(4,4)的数据。经过填充后的输入数据大小变为(6,6),将其与(3,3)的卷积核进行卷积运算得到(4,4)的输出数据。
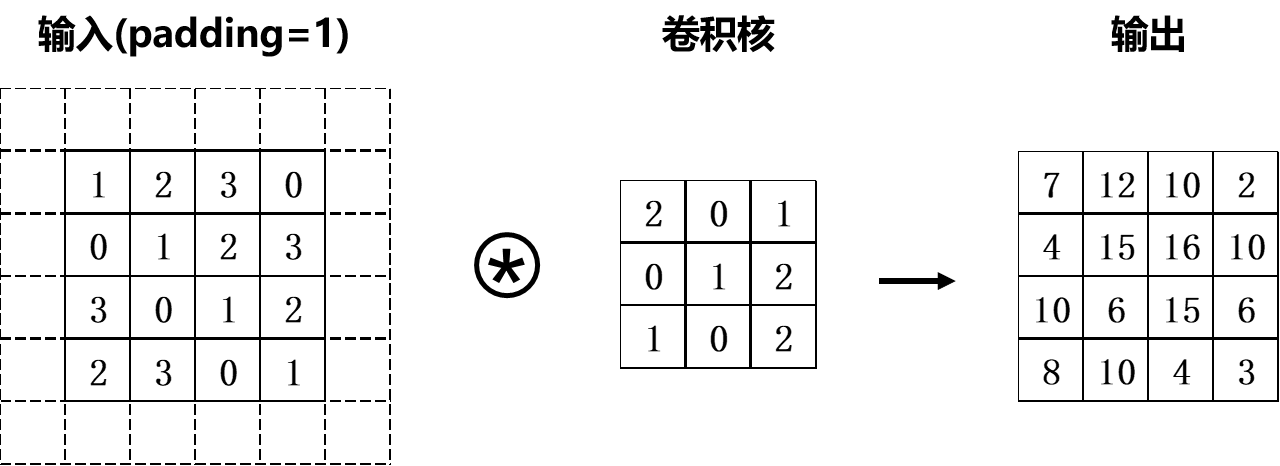
使用填充操作的目的是调整输出特征的大小。比如,将(3,3)的卷积核应用于大小为(4,4)的输入数据时,输出数据的大小变为(2,2),也就是说输出数据的大小比输入数据的大小缩减了2个元素。在深度网络中包含了众多的卷积运算操作,如果每次卷积运算都使数据的维度大小缩减,那么就有可能导致某一层数据的输出大小为1,使卷积运算无法继续运行。而填充操作则可以避免这种情况。在上述例子中所应用的填充幅度大小为1,使得输入数据和输出数据的大小得以保持,也就是说卷积运算可以在输入和输出两端维度大小不变的情况下进行。
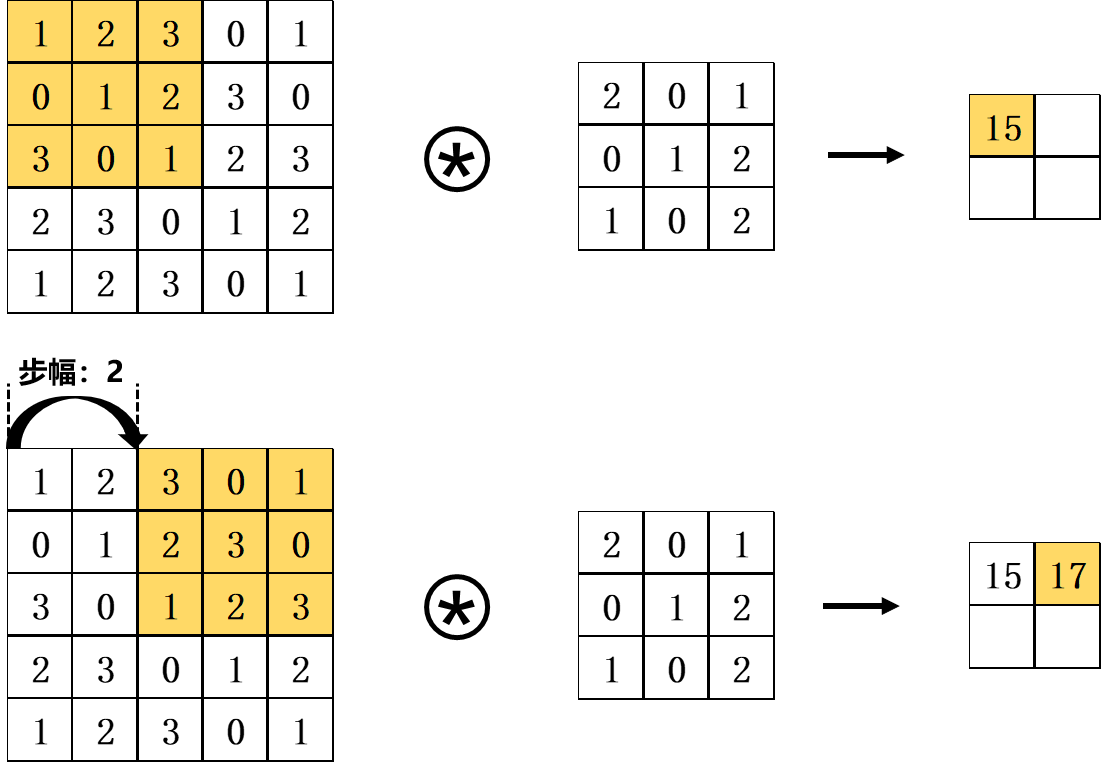
卷积的运算间隔称为步幅(Stride)。若步幅由1变为2,卷积操作则如下图所示,即运算间隔变为两个元素。
池化(Pooling)是卷积神经网络中的另一重要运算。池化具有平移不变性、旋转不变性和尺度不变性,可以起到降维、去除冗余信息的作用,从而达到降低网络复杂度、减小计算量的目的。此外,池化本身可以实现非线性运算,还可以提高模型的鲁棒性。
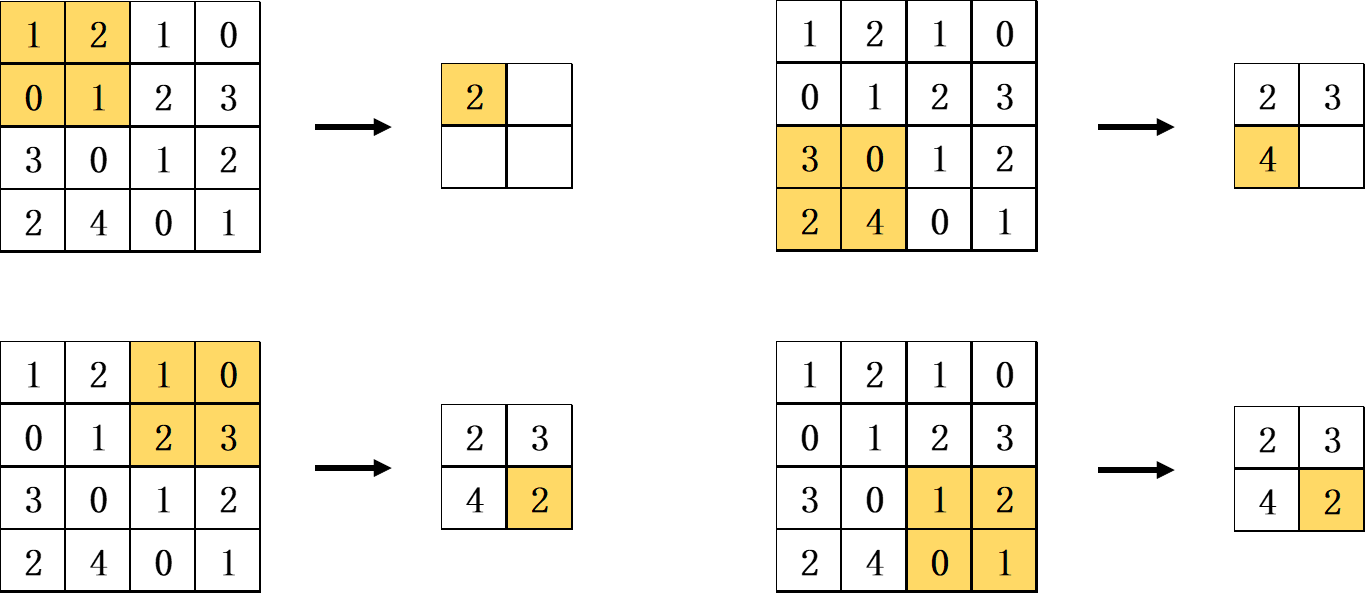
池化通常包括两种:最大值池化(Max Pooling)和平均池化(Average Pooling)。最大值池化是从目标区域中取出最大值,平均池化则是计算目标区域中的平均值,在目标检测领域通常使用最大值池化。下图是一个以步幅为2的2×2最大值池化运算示意图,其中2x2 代表目标区域的大小。其2×2窗口的移动间隔为2个元素,从其中取出最大的元素。
通过卷积运算和池化运算,卷积神经网络能有效捕捉到图像中的局部结构特征,并通过深层网络不断提高感受野(Receptive Field)的大小,从而实现对图片全局特征的提取。因此,卷积神经网络能够有效识别价量数据图表中价格和交易量的走势形态,并与未来股价进行建模。
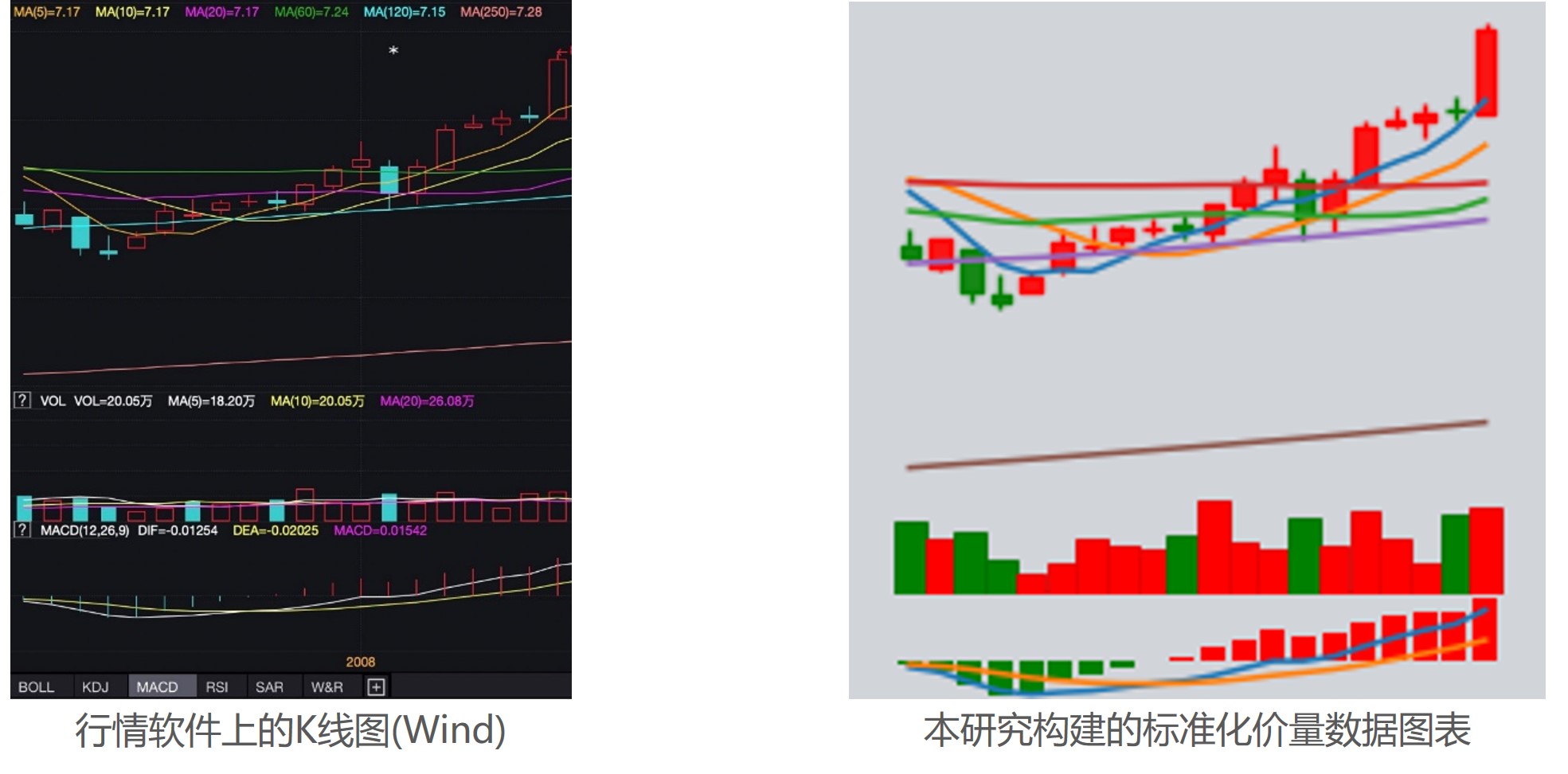
五、标准化价量数据图表为了能更好地使用卷积神经网络对价量数据图表与未来股价走势进行建模,本方法对每个个股窗口期内的价量数据构建了标准化的图表,如下图所示。该图表包含了窗口期大小为20日的价量数据,其由三部分组成:
- 图表的上部分由k线图和移动平均线构成,包含了开、高、低、收价格,以及若干股价的移动平均线,如MA5、MA10等。
- 图表的中部分由当日对应的成交量构成。
- 图表的下部分由股价的MACD信息构成,其中短期和长期移动平均线的窗口期。
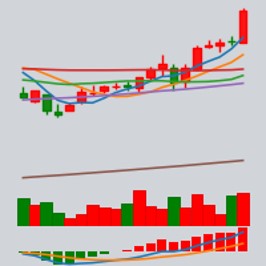
由此构成了信息丰富的标准化价量数据图表。标准化图表构建完毕后,全市场范围内从2005年至2023年期间的图表数据量达115Gb,远超于同期以序列形式表达的价量数据,后者数据量仅为2Gb不到。
六、价量数据图表卷积神经网络为了对标准化图表和股价未来走势进行建模,本方法构建了卷积神经网络,其结构下图所示。输入图片经过卷积结构后得到了512x10x10的特征图,将其摊平后得到51200维度的特征后送入一个全连接神经网络。模型的最终输出为3个概率,分别对应个股在未来截面日上收益率的百分位,即后1/3、中1/3、前1/3,以表示跌、平、涨。最终以股票上涨的概率作为因子进行选股。
在模型的实现细节上,采用Xavier、 Adam化器等技术对模型进行训练;采用训练数据外的验证集对训练中的模型进行验证,以确定最优早停(Early Stopping)时点。
通过分别训练两个不同的模型,将包含过去20日价量数据的标准化图表,与未来5日、20日的个股收益情况进行建模。在下文中,这以I{x}R{y}来表示,其中x为价量数据图表的窗口大小,y为预测未来y日的收益情况,换仓周期与y保持一致。即I20R5表示使用包含过去20日价量数据的标准化图表来预测未来5个交易日的收益情况。
七、卷积神经网络特征可视化在完成卷积神经网络的训练后,以上述标准化价量数据图表为例对模型进行输入,分别对模型中的4个卷积神经网络结构的输出在特征维度随机抽取9张特征图进行可视化,结果如下图所示。
从特征可视化结果来看,卷积层1和卷积层2作为低维度特征提取器,其关注到了整幅标准化价量数据图表中的信息,均同时涵盖了k线图、移动平均线、交易量以及MACD信息。
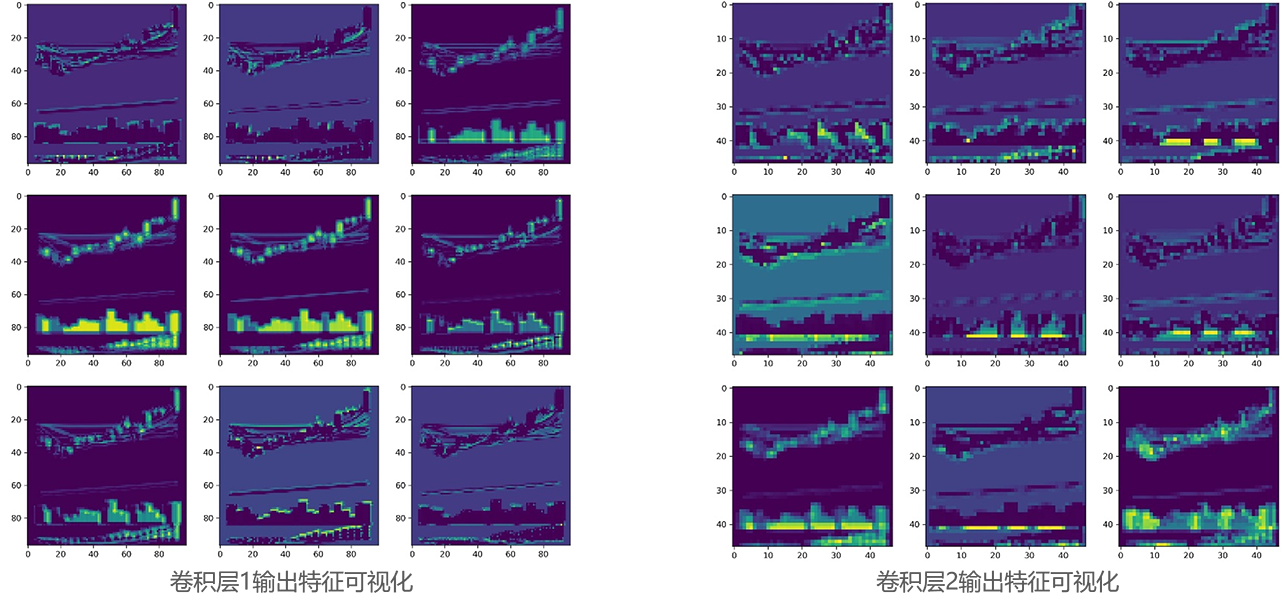
而卷积层3和卷积层4作为高维度特征提取器,其对图表中代表不同信息的不同部位的关注点开始发生分化,有的特征图重点捕捉k线图、移动平均线中的信息,而有的特征图则重点捕捉交易量以及MACD中的信息。与此同时,也有的特征图关注到了全局信息。
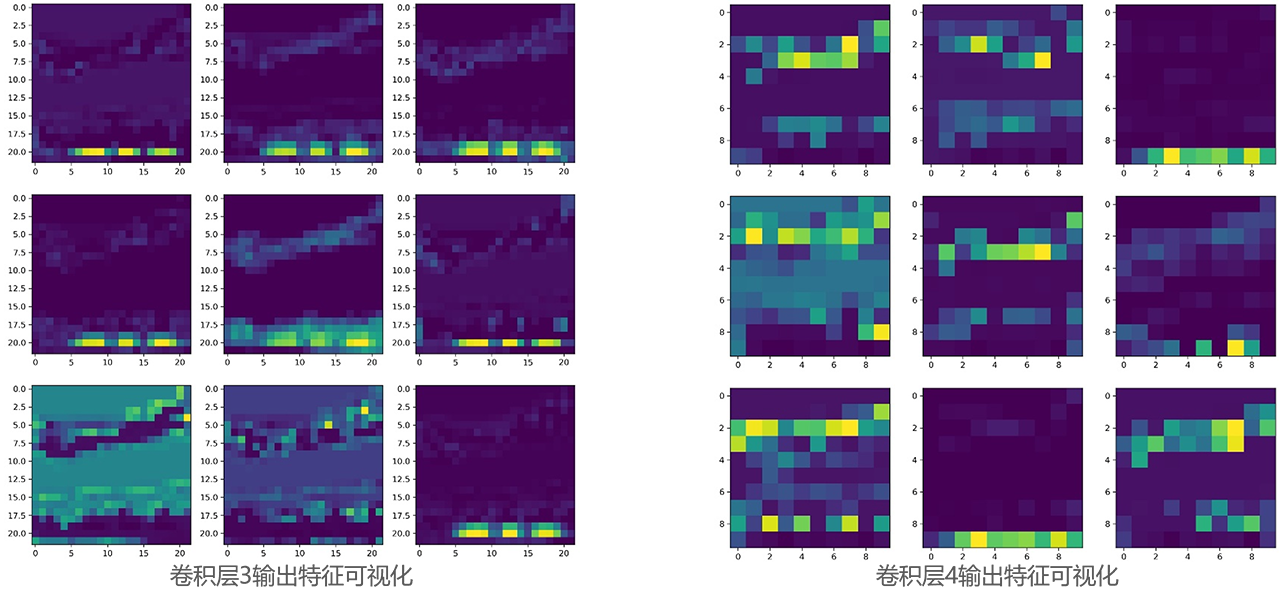
由此可见,训练后的卷积神经网络能对标准化的价量数据图表进行有效的特征提取,识别出其中的价格以及交易量形态走势信息,从而与未来的股价走势进行建模,实现对未来股价的预测。
八、训练及回测数据说明- 选股范围:全市场,沪深300,中证500,中证800,中证1000,创业板
- 股票预处理:剔除非上市、摘牌、ST/*ST、涨跌停板、上市未满1年股票
- 因子预处理:MAD去极值、Z-Score标准化、行业市值中性化
- 训练数据:全市场2005年1月~2014年12月
- 验证数据:全市场2015年2月~2019年12月(与训练数据间隔1个月防止数据暴露)
- 回测区间:2020年2月~2023年2月(与验证数据间隔1个月防止数据暴露)
- 分档方式:根据当期预测的个股价格未来上涨概率,从大到小分为10档
- 调仓周期:每5或20个交易日
- 交易费用:千分之三(卖出时收取)
I20R20表示使用包含过去20日价量数据的标准化图表来预测未来20个交易日的收益情况,并以20个交易日为周期进行调仓。本文同时比较了是否进行行业市值中性化的结果。从结果来看,I20R20在各板块的分档表现较为显著,在整体上无中性化的分档单调性优于中性化后的单调性。
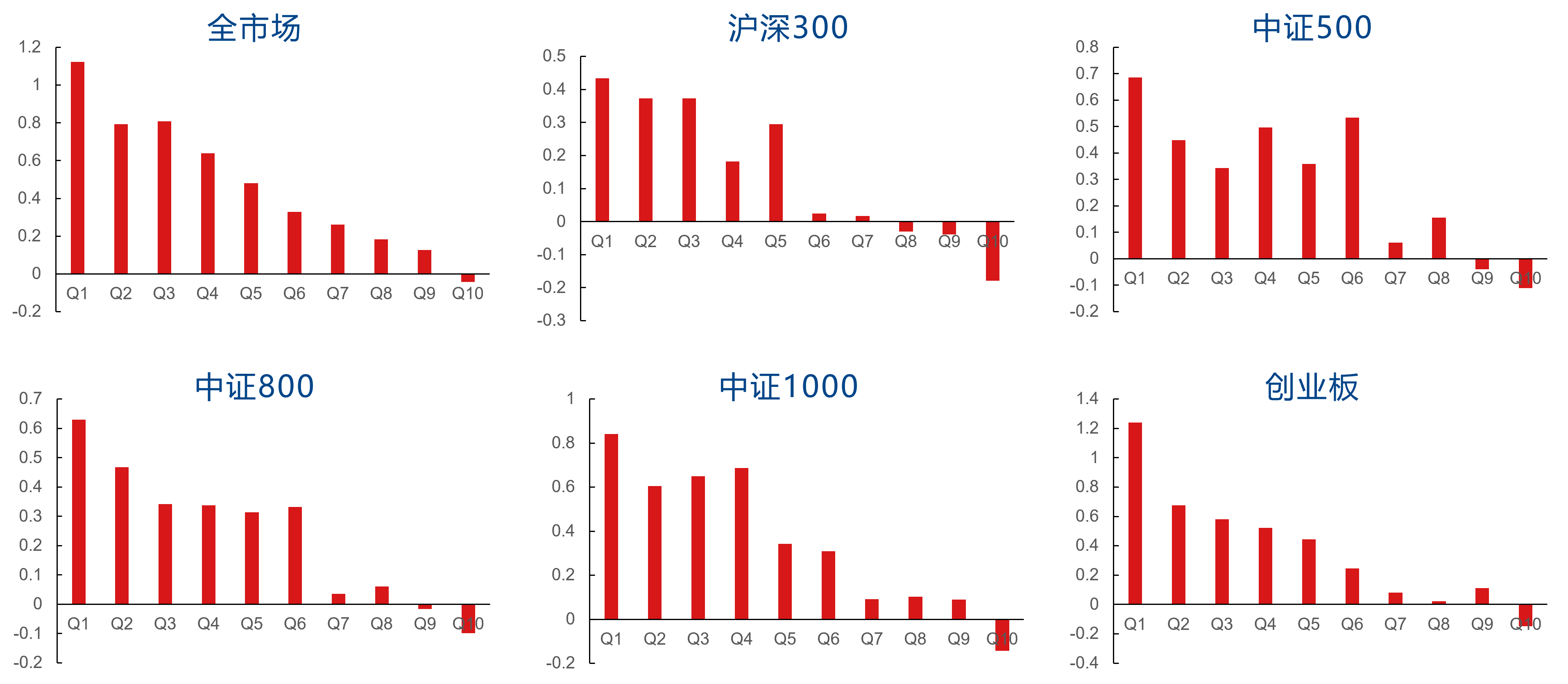
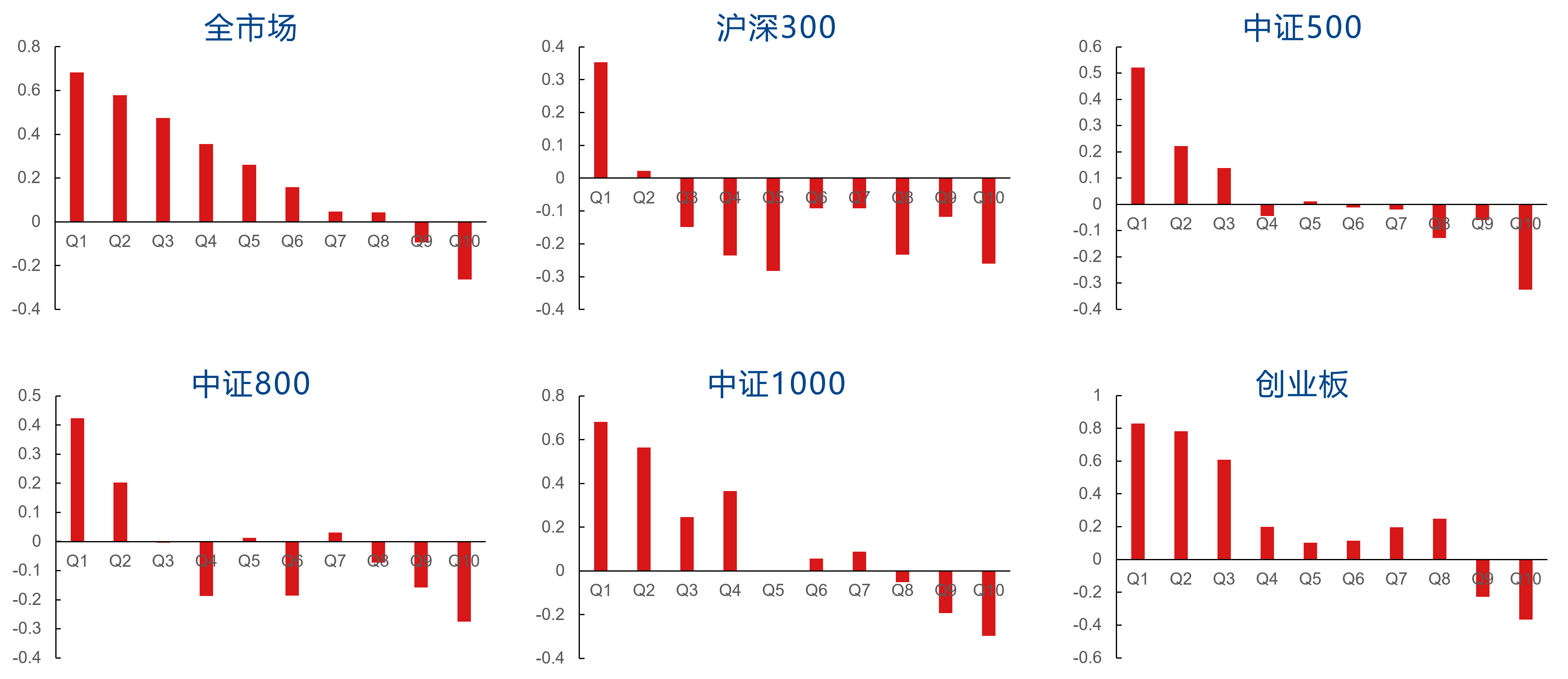
I20R20因子在行业市值中性化前的分档表现如下图所示。中性化前,I20R20因子在全市场、沪深300、中证500、中证800、中证1000、创业板中的RankIC均值分别为5.81%、5.15%、4.53%、4.61%、5.15%、6.40%,多头分别对应板块指数获得了21.06%、8.76%、10.70%、12.04%、12.54%、11.62%的超额年化收益率。
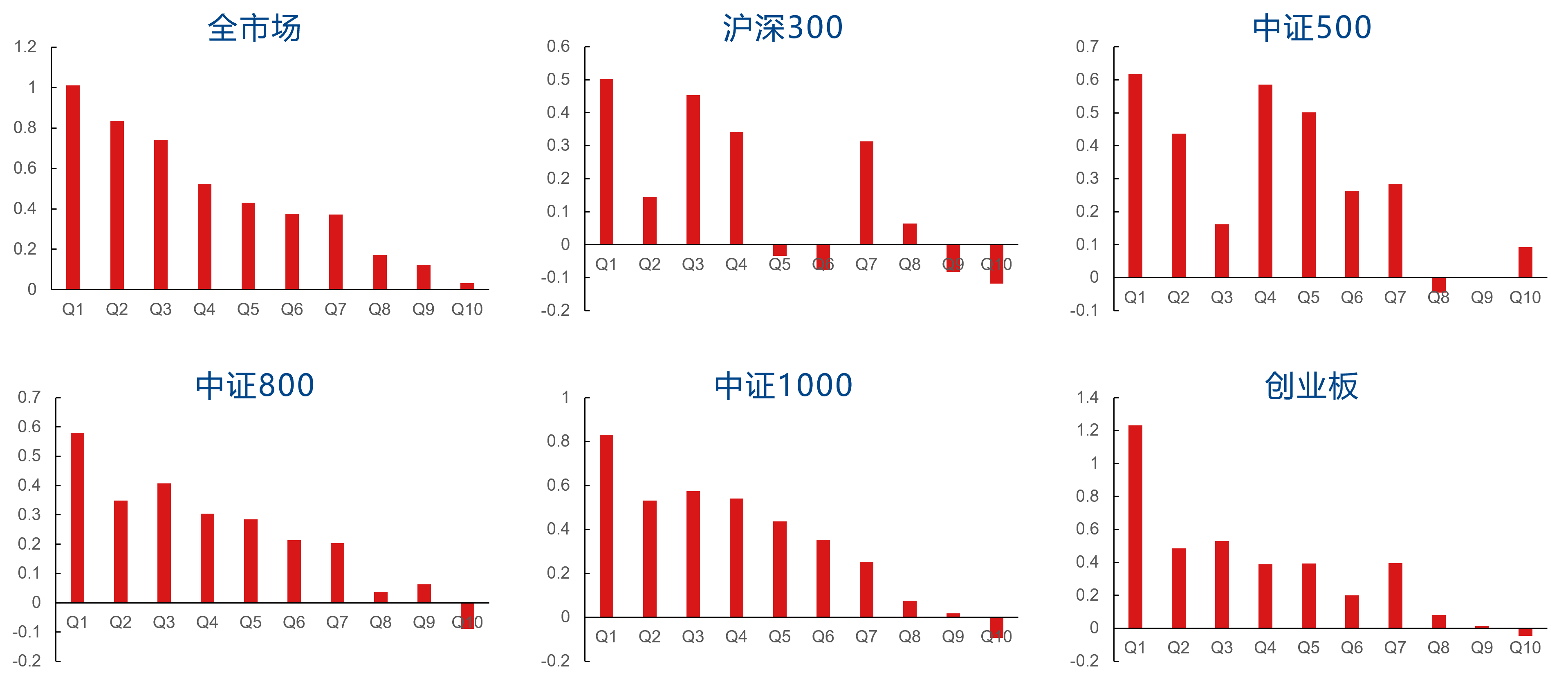
I20R20因子在行业市值中性化后的分档表现如下图所示。中性化后,I20R20因子在全市场、沪深300、中证500、中证800、中证1000、创业板中的RankIC均值分别为5.11%、4.21%、3.43%、3.75%、4.85%、5.13%,多头分别对应板块指数获得了18.82%、10.30%、9.07%、10.76%、12.29%、11.40%的超额年化收益率。
十、I20R5因子回测表现
I20R5表示使用包含过去20日价量数据的标准化图表来预测未来5个交易日的收益情况,并以5个交易日为周期进行调仓。本文同时比较了是否进行行业市值中性化的结果。从结果来看,I20R5在各板块的分档表现较为显著,在整体上无中性化的分档单调性优于中性化后的单调性。
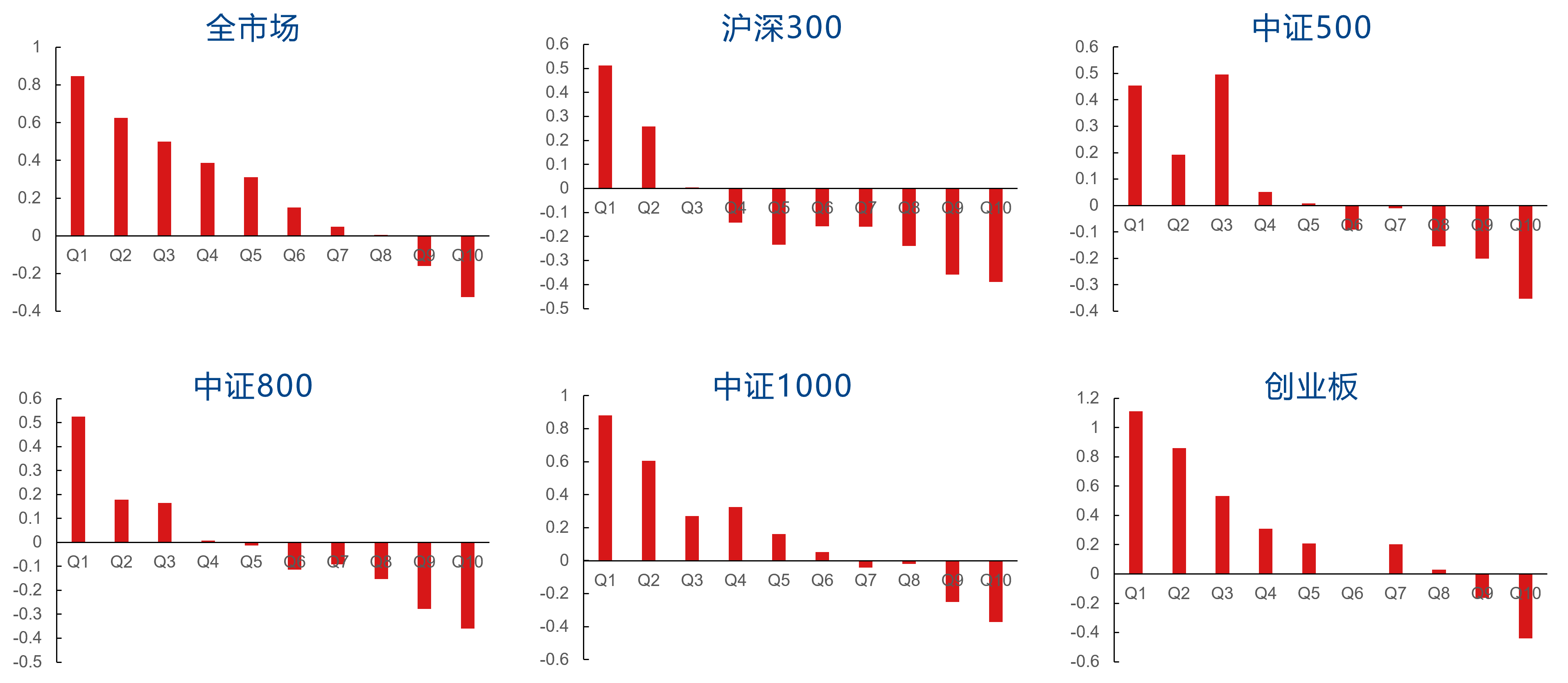
I20R5因子在行业市值中性化前的分档表现如下图所示。中性化前,I20R5因子在全市场、沪深300、中证500、中证800、中证1000、创业板中的RankIC均值分别为3.64%、3.34%、3.26%、3.19%、3.65%、4.20%,多头分别对应板块指数获得了15.93%、9.77%、3.79%、8.76、10.82%、11.32%的超额年化收益率。
I20R5因子在行业市值中性化后的分档表现如下图所示。中性化后,I20R5因子在全市场、沪深300、中证500、中证800、中证1000、创业板中的RankIC均值分别为3.01%、1.39%、2.60%、2.04%、3.00%、3.41%,多头分别对应板块指数获得了12.34%、5.72%、5.21%、6.21%、6.95%、5.89的超额年化收益率。
十一、总结与展望
本研究探讨了卷积神经网络在选股策略中的应用。通过构建标准化的价量数据图表,设计了卷积神经网络识别其中价格和交易量的走势形态,将其与未来股价进行建模,从而实现对未来股价的预测。以20日窗口期的价量数据图表为模型输入,分别对未来20日和5日的股价走势进行预测,从而构建出I20R20因子和I20R5因子。
以2020年2月至2023年2月作为样本外回测区间,实证分析结果表明I20R20因子和I20R5因子的分档收益较为显著,均取得了较为可观的超额收益。
展望未来,可以采用包含更长窗口期的标准化价量数据图表来对未来股价进行预测。而对于机器学习量化选股策略而言,可探索更多的人工智能模型。
参考文献(部分)
[1] Jiang J, Kelly B, Xiu D. (Re‐) Imag (in) ing price trends[J]. The Journal of Finance, 2023, 78(6): 3193-3249.
[2] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.
[3] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[4] 斋藤康毅. 深度学习入门:基于Python的理论与实现. 北京:人民邮电出版社, 2018.