股价预测之多模态多尺度
【摘要】
在前序研究《深度学习研究报告:基于卷积神经网络的股价走势AI识别与分类》中,创新性地采用基于深度学习的图像识别技术,将价量数据图表与未来股价走势进行建模,以实现股票价格预测。
本文以“多模态、多尺度”为题,基于AI看图初版模型,在日度价量数据图表的基础上,加入了高频因子数据、日频时序数据、周度价量数据图表,采用4个独立的深度时序模型和深度卷积模型进行多模态、多尺度的特征提取,并同时采用回归损失和分类损失以端到端的方式进行模型训练,有效提升了模型对未来股价的预测能力,取得了更为显著的超额收益。
一、AI看图基于价量数据对未来股价走势进行预测作为一类重要的机器学习量化选股策略,在过去受到了广泛的研究和应用。由于个股的价量数据是随着交易活动的进行而产生的,其本质上是关于时间的一组序列。因此,为了建模价量数据与未来股价走势之间的关系,大多数研究方法自然而然地使用了循环神经网络(Recurrent Neural Network,RNN)或Transformer这两大类时序模型。
在这些方法中,模型的输入是关于价量数据的一维或多维数组,输出则是股价的未来走势。然而,尽管时序模型在一定程度上能够捕捉到价量序列中诸如价格、交易量的上涨或下跌及其相互交织的高维信息,但其无法对价格和交易量的走势形态及其变化进行有效识别。
举个例子对此进行解释。以人类视角来看,通常在对股价的未来走势进行预测时,并不会选择直接观测一组关于价量的序列,因为能从中捕获到的不只是数字上的涨跌。为了能更好地捕捉到价格和交易量的形态走势,通常会选择观测包含k线图、移动平均价、交易量、MACD数据的图表,而不是一组纯粹的数字。
基于以上观点,在前序研究《深度学习研究报告:基于卷积神经网络的股价走势AI识别与分类》中,创新性地采用基于深度学习的图像识别技术,将价量数据图表与未来股价走势进行建模,以实现股价预测,整体模型结构如下图1所示。
二、多模态多尺度股价预测模型
2.1、模型结构
本文以“多模态、多尺度”为题,基于AI看图初始版本模型进行了大幅改进,新的模型结构如下图2所示。本文模型在日度价量数据图表的基础上,加入了高频因子数据、日频时序数据、周度价量数据图表,采用4个独立的深度时序模型和深度卷积模型进行多模态、多尺度的特征提取,并同时采用回归损失和分类损失以端到端的方式进行模型训练,有效提升了模型对未来股价的预测能力。
2.2、改进思路
本文模型主要有以下几个改进思路:
(1)多模态:尽管价量数据图表所蕴含的信息完全来自于原始的价量时序数据,但以不同模态(图表数据与时序数据)表征的数据,在深度学习模型中所捕获的信息具有较大差异。通常而言,时序模型能够有效捕获到原始价量数据中较为抽象的数量变化关系,而卷积模型则能够更有效地识别到价量数据图表中的形态走势。为了验证这一观点,以AI看图初始版本模型的预测结果作为卷积模型因子,以GRU模型的预测结果作为时序模型因子,二者虽同根同源,但它们的因子历史相关系数仅约为35%,具有较大的差异性。因此,本文分别采用时序模型和卷积模型,同时以时序价量数据和标准化价量数据图表作为输入,并对不同模态的特征进行融合,充分发挥不同模型、不同模态数据的各项优点,以端到端的方式进行模型训练和未来股价预测。
(2)多尺度:不同频率的价量数据,蕴含着不同维度的信息。日内高频数据反映了交易日中的博弈,但缺乏长周期的趋势信息;日频、周频数据则能够有效补充日内高频数据所难以表征的历史走势。因此,本文采用了1分钟频、日频、周频三种不同频率的价量数据作为改进后模型的原始输入数据。其中,对于1分钟频价量数据,采用高频数据日度因子化的方式,从中构建出了55组特征信息,再将多日的日度因子送入时序模型。这样的特征提取方法不仅能够更有效地捕获日内股价信息,而且能够有效降低模型复杂度,减少过拟合,提升样本外的股价预测效果。
(3)轻量化:尽管本文模型包含了4个独立的深度时序模型和深度卷积模型以实现多模态、多尺度的特征提取,但每个独立子模型的参数量都进行了大幅度的轻量化。以其中的卷积模型为例,其整体结构与AI看图初始模型一致,但每一个卷积模块的特征维度只有后者的1/4。轻量化不仅避免了因为多模态多尺度数据所带来的模型过拟合风险,而且减少了模型在训练过程中的巨额计算资源依赖和耗时,同时还提升了模型在训练完毕后的样本外股价预测效率,使得训练好的模型甚至能够在一台轻薄笔记本上运行。
(4)多头输出:在本文模型的输出端,包含了两个分支。其中一个分支以未来股价的绝对收益作为学习目标;另一个分支则以未来股价的涨、平、跌三类别作为学习目标。这两种损失函数是学术界和产业界在该领域研究上最常用的方式。从实际经验来看,以绝对收益作为学习目标的方式,通常能够得到IC均值和胜率较高、分档单调性较好的因子,但其多头收益不会特别显著;而采用涨平跌分类作为学习目标的方式,通常可以得到多头收益显著的因子,但其IC均值和胜率不会特别突出。因此,本文希望结合两种学习目标的优点,得到不仅IC均值和胜率较高、分档单调性较好,且多头收益显著的因子。具体而言,在训练过程中,两个分支分别以均方误差和交叉熵作为损失函数,两个损失在加总后以端到端的方式进行梯度回传。在模型训练完毕的样本外预测阶段,通过同时结合两个分支的预测结果,提升了模型的股价预测准确率,从而使得股票组合获得更为客观的超额收益。
三、实证分析3.1 数据说明
- 选股范围:全市场,沪深300,中证500,中证800,中证1000,国证2000,创业板
- 股票预处理:剔除非上市、摘牌、ST/*ST、涨跌停板、上市未满1年股票
- 训练数据:全市场2008年1月~2016年12月
- 验证数据:全市场2017年2月~2019年11月(与训练数据间隔1个月防止数据暴露)
- 测试数据:2020年1月~2024年10月(与验证数据间隔1个月防止数据暴露)
- 组合构建:根据当期预测的个股价格未来上涨概率,从大到小分为10档
- 回测路径:以多路径回测均值作为统计数据
- 调仓策略:每20个交易日,根据模型在t日的预测结果,以t+1日均价买入,t+1+n日均价卖出
- 交易费率:双边千分之三(卖出时收取)
3.2 对比提升
以2020/01/01 ~ 2024/10/31作为样本外回测区间,以20日作为换仓周期,本文模型预测结果在全市场、沪深300、中证500、中证800、中证1000、国证2000、创业板的RankIC均值分别为8.7%、7.9%、6.6%、6.9%、8.2%、8.7、10.4%,RankIC胜率分别为86.7%、69.0%、73.5%、75.2%、84.8%、86.1%、89.2%。以全市场作为回测统计口径,对比AI看图初始版本,本文模型的RankIC均值提升了3.0%,RankIC胜率提升了7.8%。
3.3 本文模型因子与Barra风格因子相关性本文模型因子与Barra风格因子的相关系数如下表所示。整体而言,本文模型因子与Barra风格因子的相关性较低,其中相关性最高的三个Barra风格因子为流动性因子、波动率因子和市值因子,相关系数分别为-18%、-16%和-8%。

3.4 实证分析(全市场)
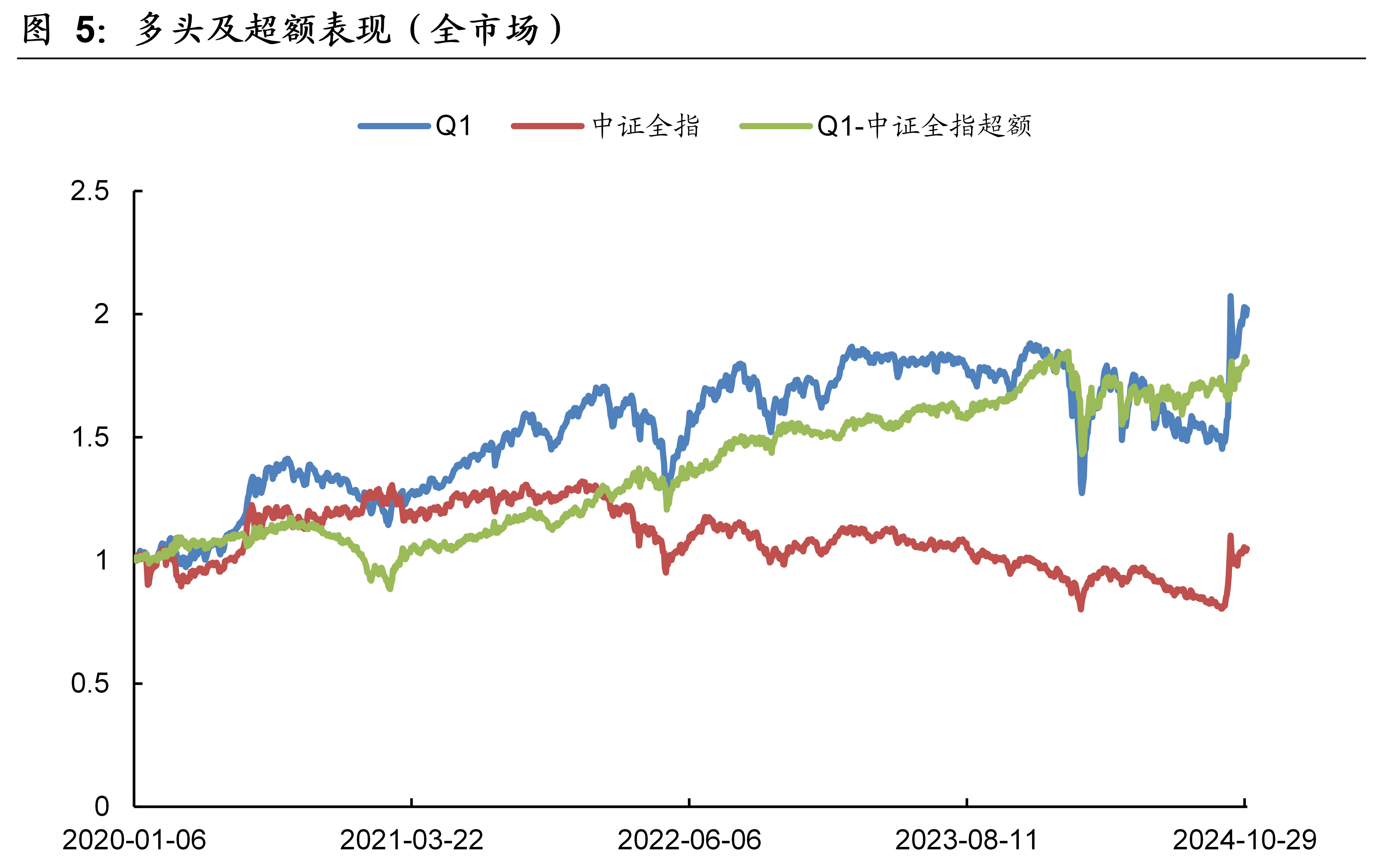
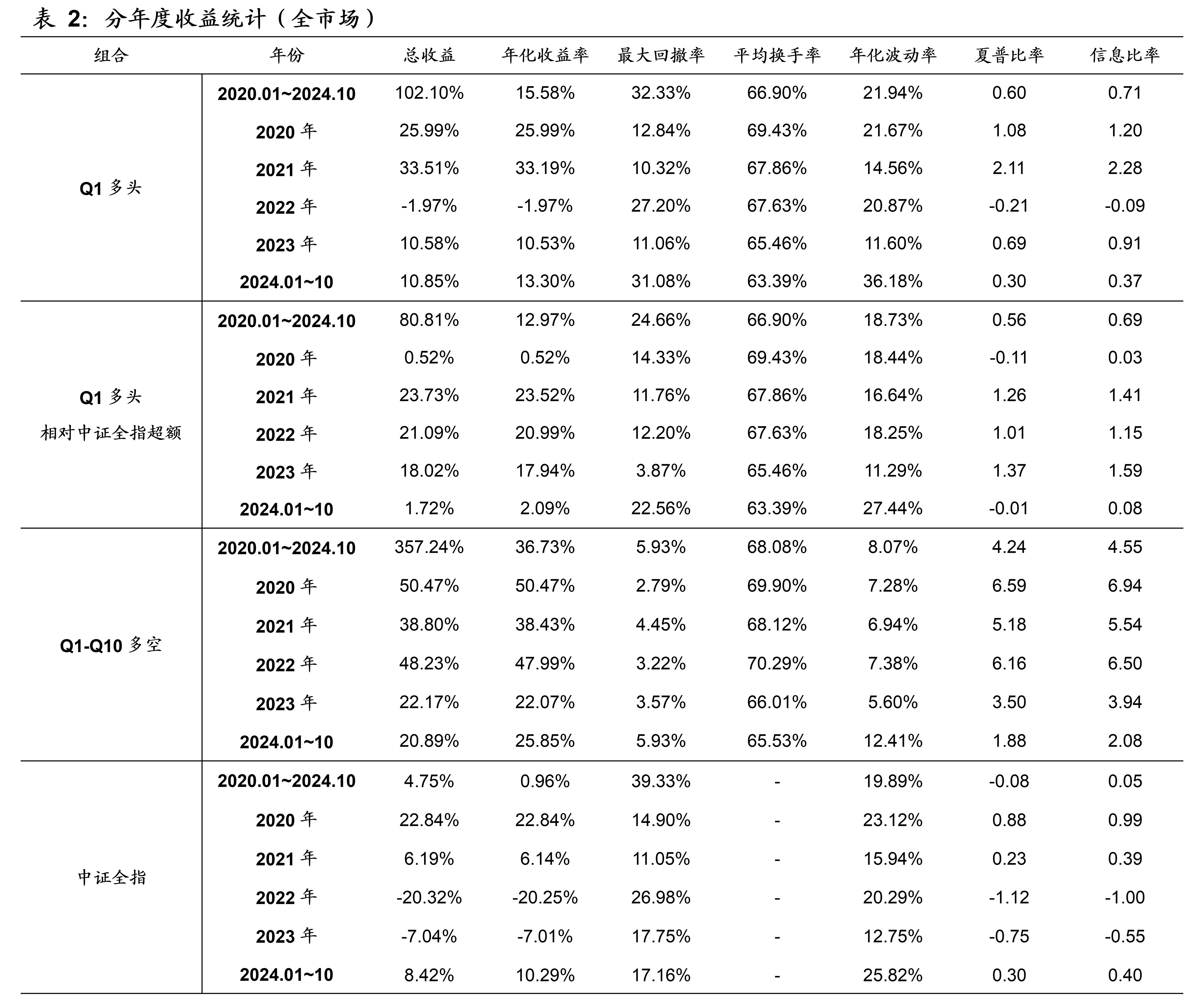
本文模型在全市场的样本外回测表现如下图表所示。本文模型因子在全市场的10分档收益单调性显著,RankIC历史均值为8.7%、胜率为86.7%。2020年~2024年10月期间,双边千三计费后的多头年化收益率为15.58%,相比同期的中证全指取得了12.97%的超额年化收益率。
3.5 实证分析(沪深300)
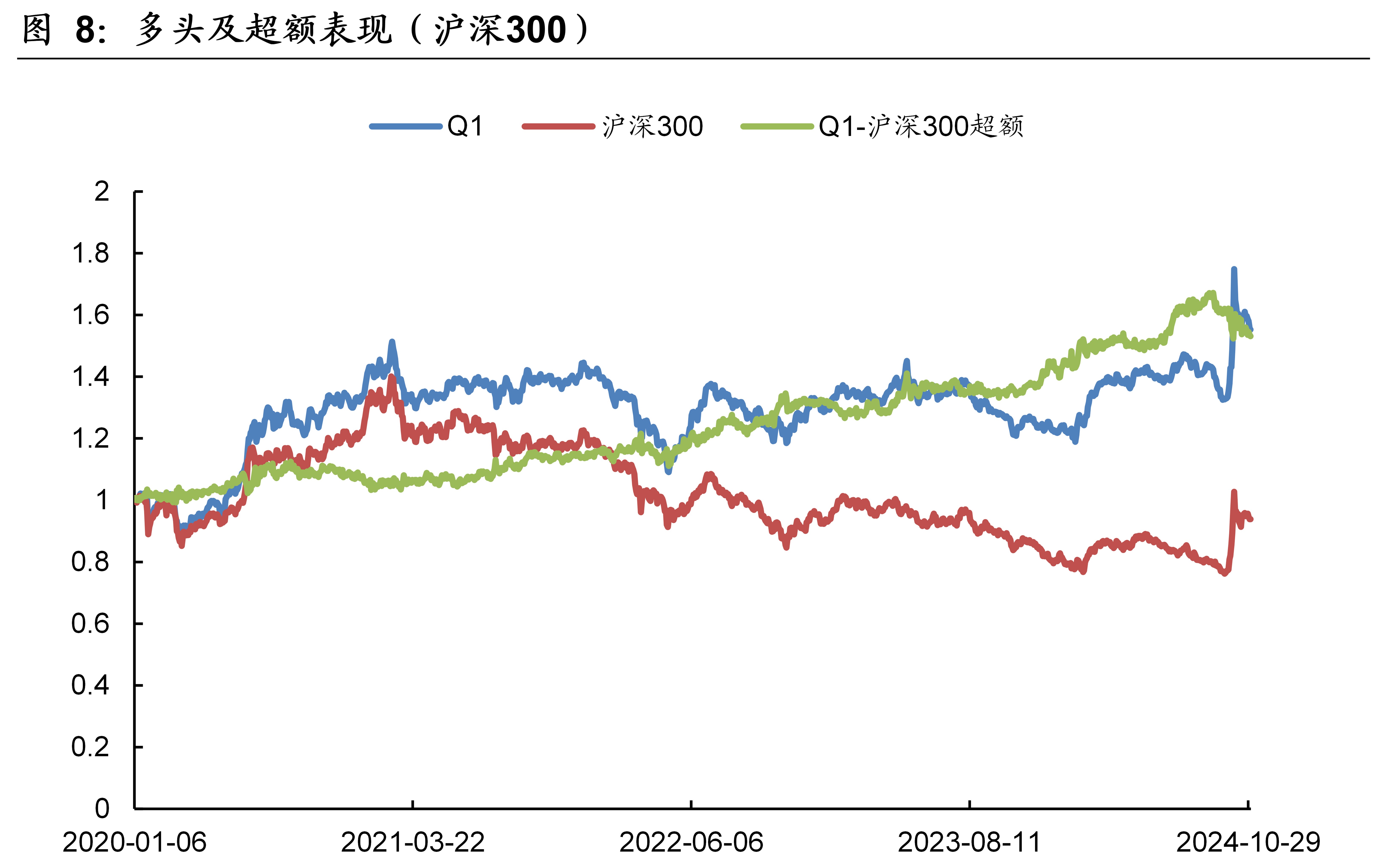
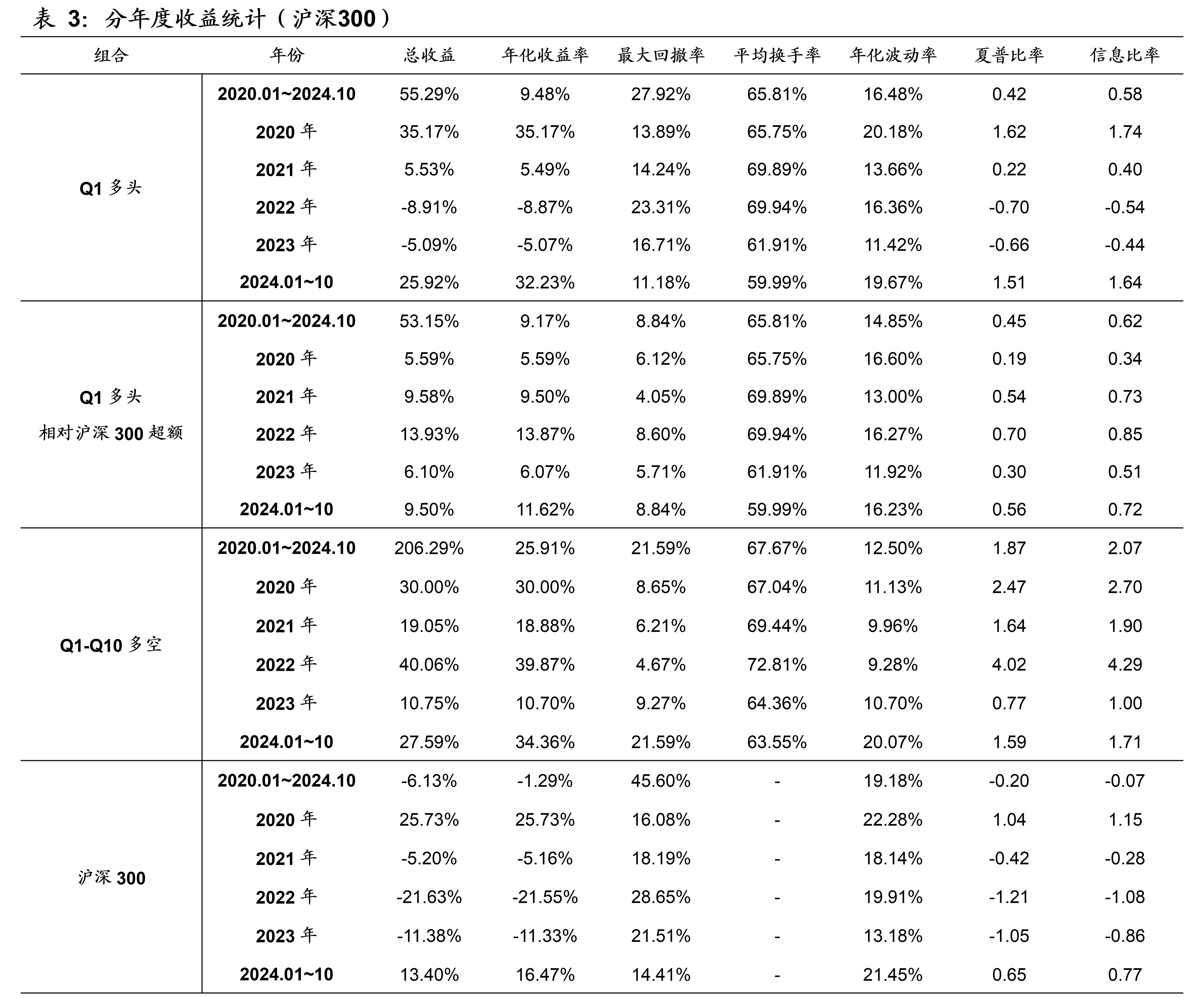
本文模型在沪深300的样本外回测表现如下图表所示。本文模型因子在沪深300的10分档收益单调性显著,RankIC历史均值为7.9%、胜率为69.0%。2020年~2024年10月期间,双边千三计费后的多头年化收益率为9.48%,相比同期的沪深300指数取得了9.17%的超额年化收益率。
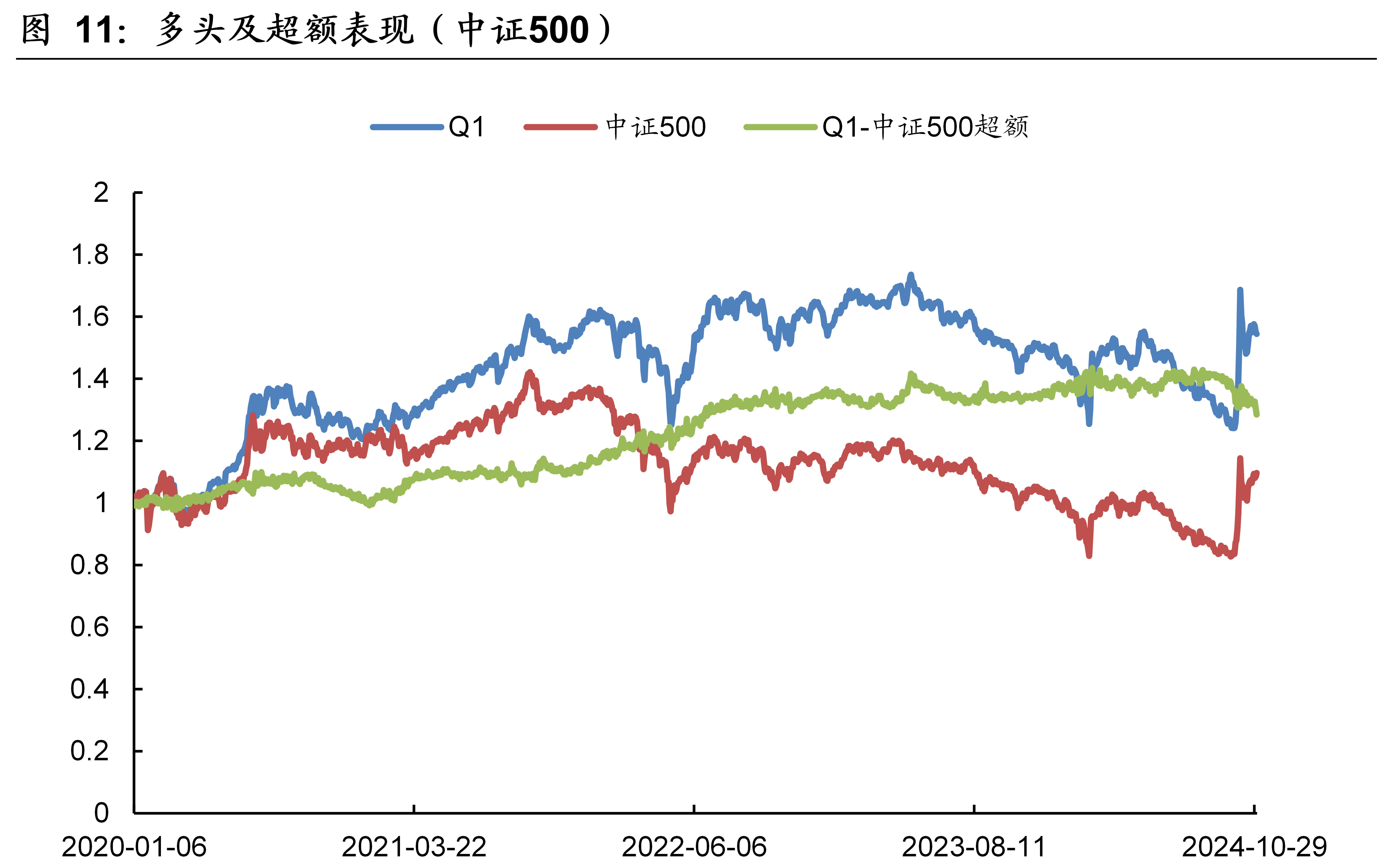
3.6 实证分析(中证500)
本文模型在中证500的样本外回测表现如下图表所示。本文模型因子在中证500的10分档收益单调性显著,RankIC历史均值为6.6%、胜率为73.5%。2020年~2024年10月期间,双边千三计费后的多头年化收益率为9.36%,相比同期的中证500指数取得了5.30%的超额年化收益率。

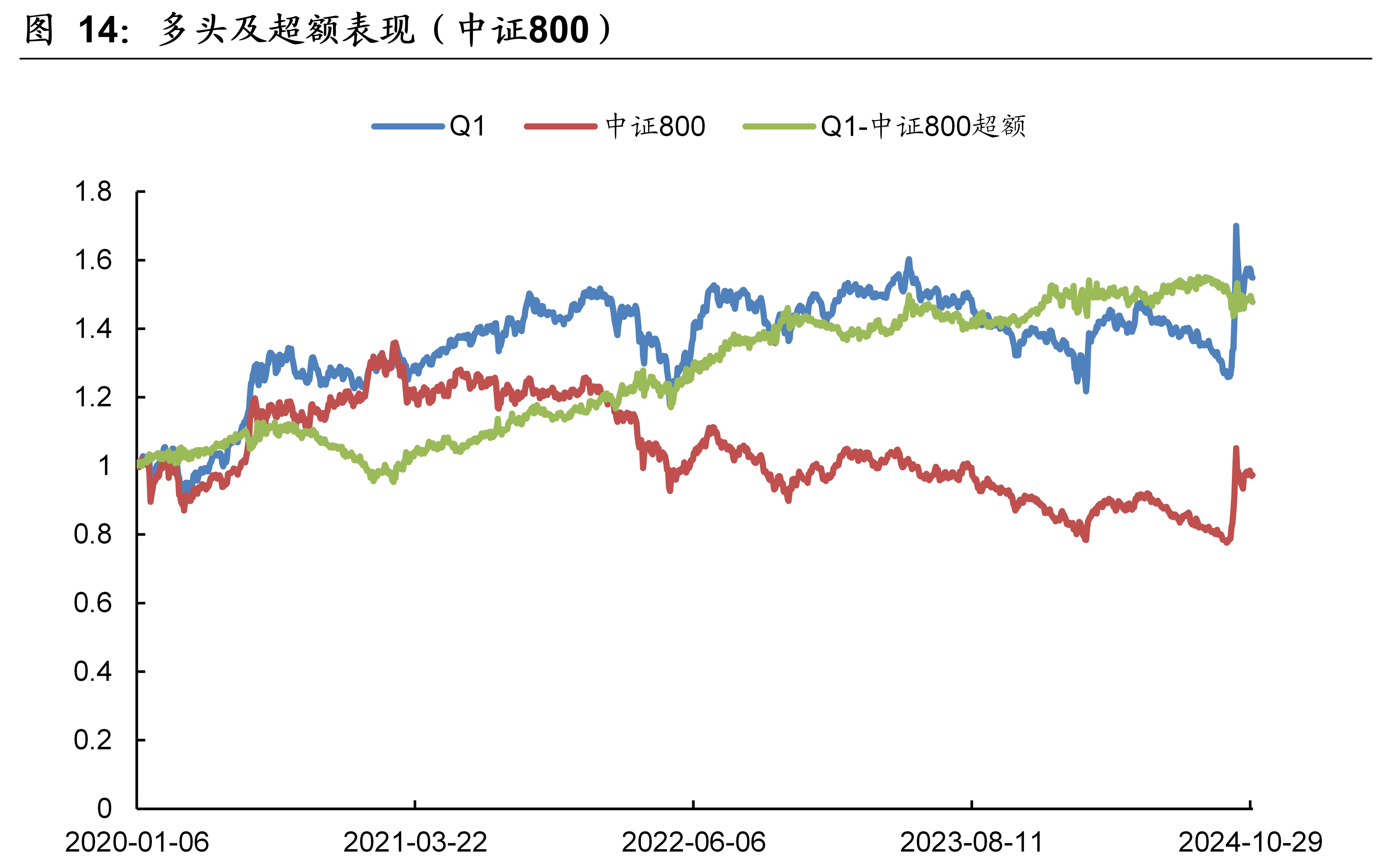
3.7 实证分析(中证800)
本文模型在中证800的样本外回测表现如下图表所示。本文模型因子在中证800的10分档收益单调性显著,RankIC历史均值为6.9%、胜率为75.2%。2020年~2024年10月期间,双边千三计费后的多头年化收益率为9.43%,相比同期的中证800指数取得了8.38%的超额年化收益率。
3.8 实证分析(中证1000)
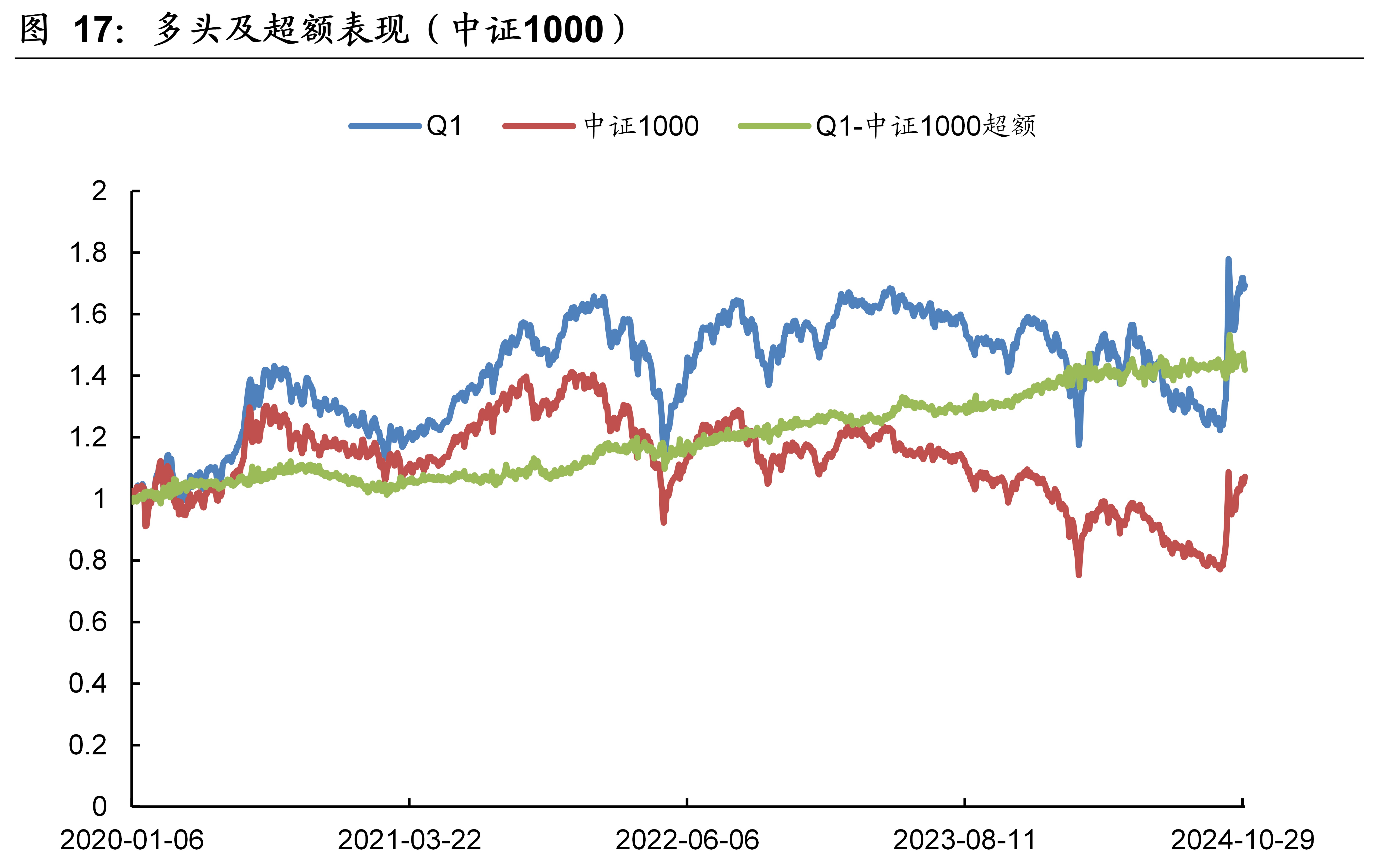
本文模型在中证1000的样本外回测表现如下图表所示。本文模型因子在中证1000的10分档收益单调性显著,RankIC历史均值为8.2%、胜率为84.8%。2020年~2024年10月期间,双边千三计费后的多头年化收益率为11.45%,相比同期的中证1000指数取得了7.47%的超额年化收益率。


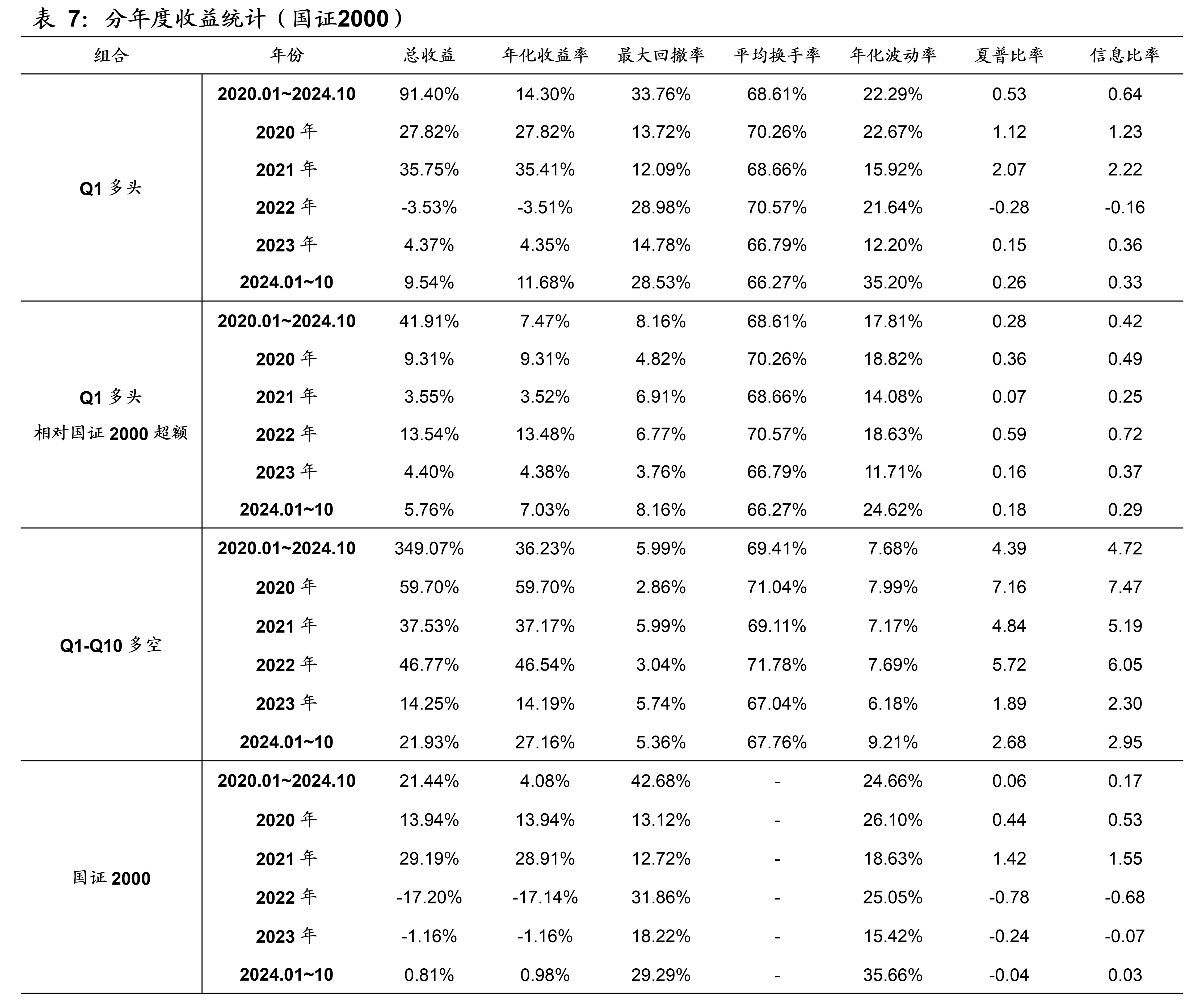
3.9 实证分析(国证2000)
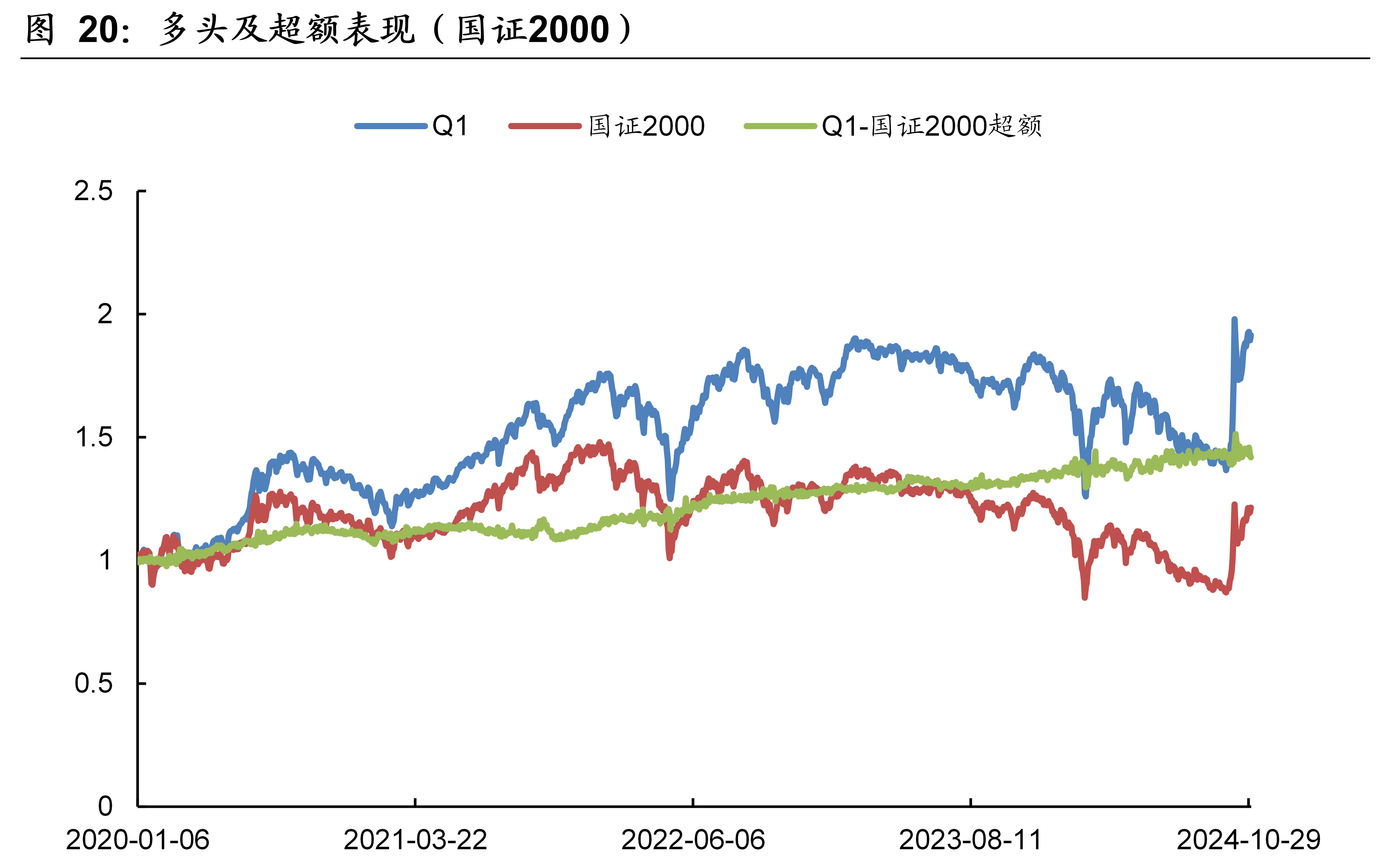
本文模型在国证2000的样本外回测表现如下图表所示。本文模型因子在国证2000的10分档收益单调性显著,RankIC历史均值为8.7%、胜率为86.1%。2020年~2024年10月期间,双边千三计费后的多头年化收益率为14.30%,相比同期的国证2000指数取得了7.47%的超额年化收益率。
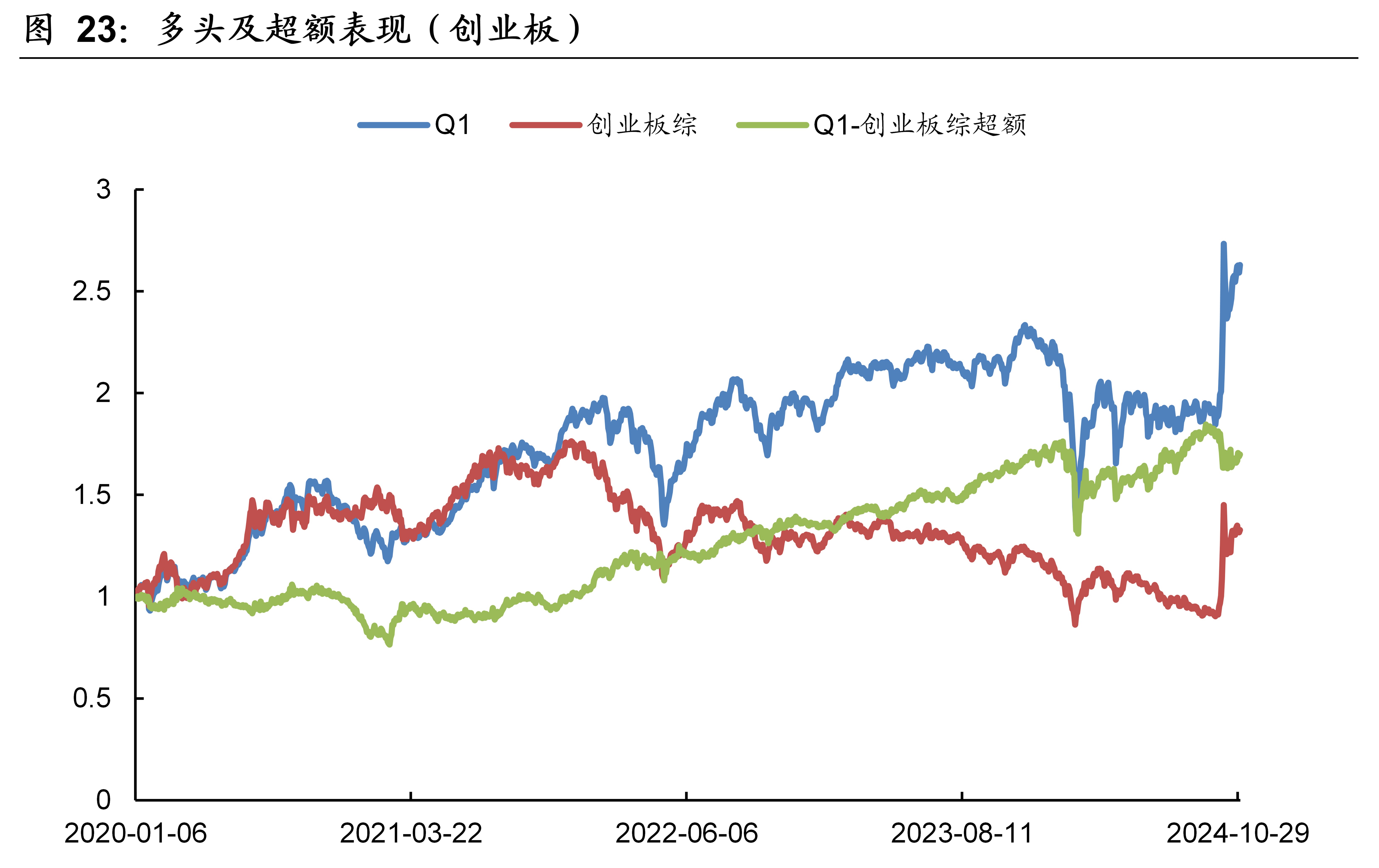
3.10 实证分析(创业板)
本文模型在创业板的样本外回测表现如下图表所示。本文模型因子在创业板的10分档收益单调性显著,RankIC历史均值为10.4%、胜率为89.2%。2020年~2024年10月期间,双边千三计费后的多头年化收益率为22.01%,相比同期的创业板综指取得了11.52%的超额年化收益率。

四、卷积模型与时序模型
若需进一步了解卷积模型和时序模型,可参考前序研究《深度学习研究报告:基于卷积神经网络的股价走势AI识别与分类》。
五、总结与展望在前序研究《深度学习研究报告:基于卷积神经网络的股价走势AI识别与分类》中,创新性地采用基于深度学习的图像识别技术,将价量数据图表与未来股价走势进行建模,以实现股票价格预测。
本文以“多模态、多尺度”为题,基于AI看图初版模型进行了大幅改进。本文模型在日度价量数据图表的基础上,加入了高频因子数据、日频时序数据、周度价量数据图表,采用4个独立的深度时序模型和深度卷积模型进行多模态、多尺度的特征提取,并同时采用回归损失和分类损失以端到端的方式进行模型训练,有效提升了模型对未来股价的预测能力,取得了更为显著的超额收益。
以2020/01/01 ~ 2024/10/31作为样本外回测区间,每20个交易日进行换仓,本文模型预测结果在全市场、沪深300、中证500、中证800、中证1000、国证2000、创业板的RankIC均值分别为8.7%、7.9%、6.6%、6.9%、8.2%、8.7、10.4%,RankIC胜率分别为86.7%、69.0%、73.5%、75.2%、84.8%、86.1%、89.2%。以全市场作为回测统计口径,对比AI看图初始版本,本文模型的RankIC均值提升了3.0%,RankIC胜率提升了7.8%。
以2020/01/01 ~ 2024/10/31作为样本外回测区间,基于本文模型因子在全市场、沪深300、中证500、中证800、中证1000、国证2000、创业板分别构建10分档多头股票组合,双边千三计费后,多头股票组合分别相对对应板块指数取得了12.97%、9.17%、5.30%、8.38%、7.47、7.47%、11.52的超额年化收益率。
整体而言,本文模型因子与Barra风格因子的相关性较低,其中,相关性最高的三个Barra风格因子为流动性因子、波动率因子和市值因子,相关系数分别为-18%、-16%和-8%。
本报告以研发为主要目的,对模型进行了严谨的训练、验证、以及回测。其中,训练样本为2008~2016年数据,验证样本为2017~2019年数据,回测样本为2020~2024年数据。从理论上来说,通过加入更新、更多的训练样本,结合滚动训练等方式,能够进一步提升模型对未来股价的预测能力,取得更为显著的超额收益。